整个语音识别系统主要构成有四个部分:语音信号处理和特征的提取模块;语音识别的声学模型;语音识别的语言模型;语音识别的解码和搜索部分。系统流程图如下图所示:
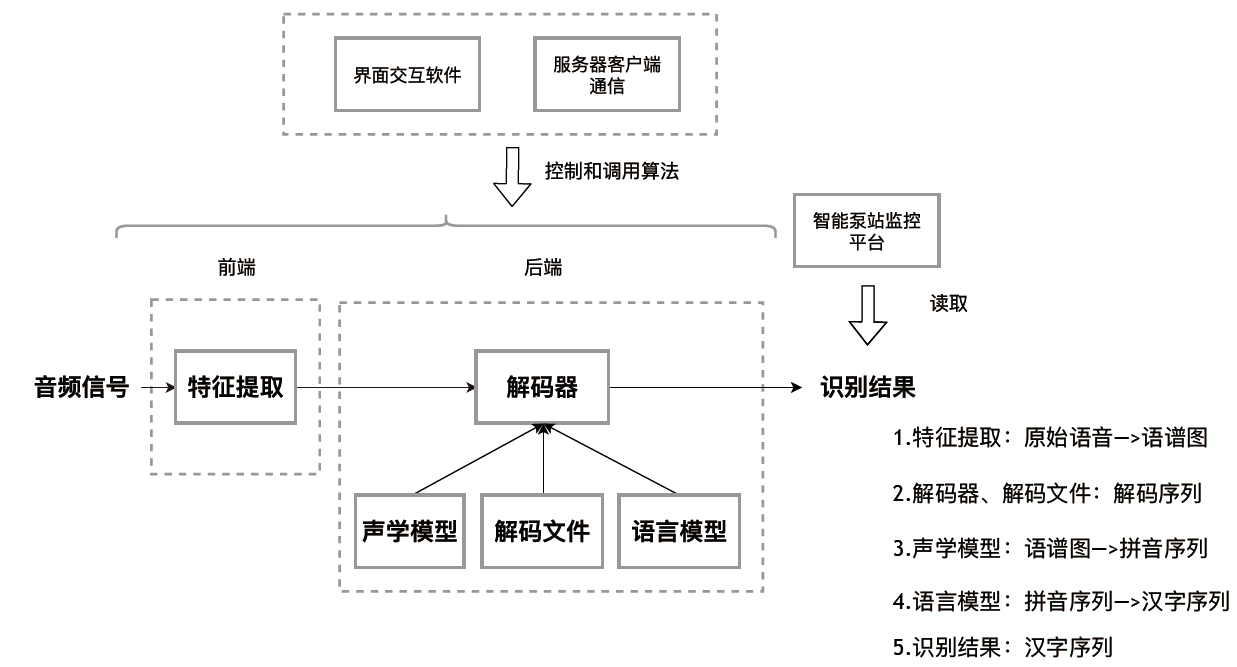
整个语音识别的过程可以用贝叶斯理论来描述,假设输入的音频序列为$O={o{1}, o{2}, \cdots, o{n}}$,输出为文本序列为$W={w{1}, w{2}, \cdots, w{n}}$。目的是构建一个模型,使得$\prod{n} P\left(W{n} | O_{n}\right)$最大,也就是训练集中n个样本的后验概率最大。单独拿出一个样本的后验概率使用贝叶斯公式可以得到:
进一步可得:
这里$P(W)$是输出词序列的概率,用语言模型来刻画,$P(O | W)$为似然概率,使用声学模型来表达。
数据集构建
语音数据构建主要分为两种,一是公开数据集—>日常对话,二是特定数据集—>控制命令。
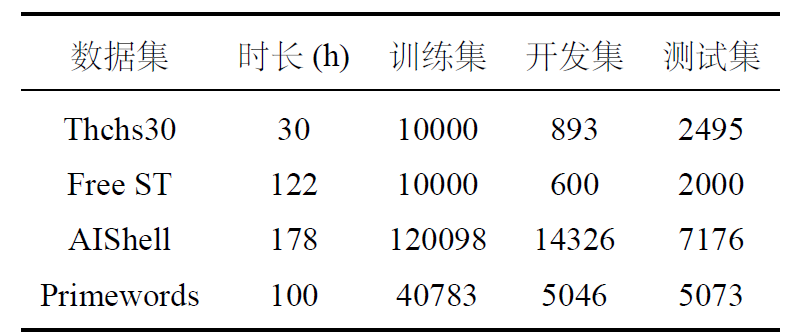
所搜集的公开语音数据集是THCHS30、ST-CMDS、AIShell等数据集,这几个数据集是中文语音数据集,基本数据格式如下图所示:

基本信息如下:
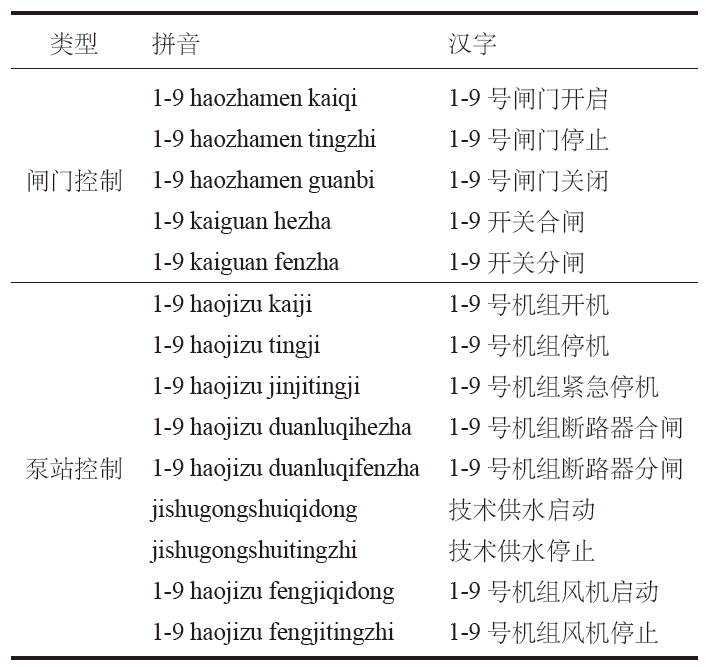
针对实际的工业控制命令,我们进行专门的语音采集和录制。环境是和实际的泵站控制室一致,安静、近场。这里使用单粒麦克风进行录制,录制的格式与上边格式一致。
语音信号预处理
语音信号预处理是为了将原始语音信号转换成CNN网络输入的语谱图。CNN的输入层是200维的特征值序列。输出拼音的表示大小是1422,即1421个拼音+1个空白块。预测结果是返回语音识别后的拼音符号列表。
语音信号的预处理过程用到的技术是:预加重(pre-emphasis)、
分帧(enframing)、加窗(windowing)
预加重
预加重可以使得语音信号的频谱信号分布更加均衡。预加重一般是用
60db/octave数字滤波器频率特性完成的。过滤器公式给出:
其中$u$是预加重系数。
分帧
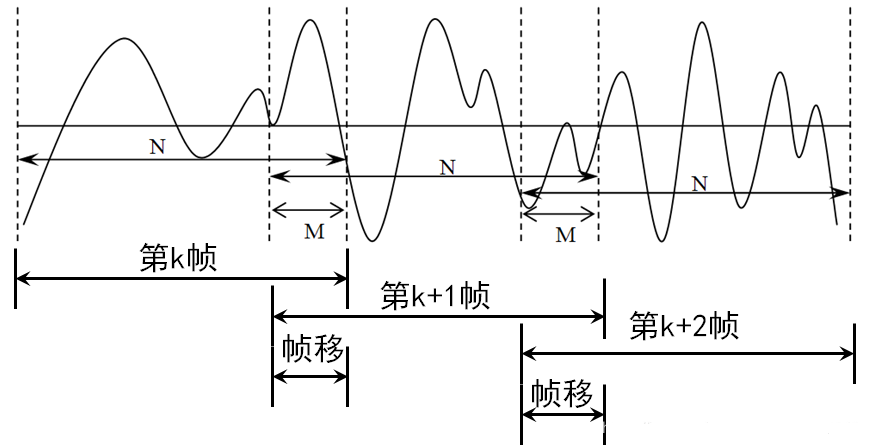
使用预先设计好的窗函数处理被分帧分成的多个小片段。通过这种方法在一定程度上解决语音信号帧信号之间的不连续性问题。每一个小段作为语音信的单位,称为帧(frame)。以帧为单位可以分析语音信号的短时特性,从而进一步进行频谱等处理。分帧一般相邻帧之间有交叉重叠,交叉部分叫做帧移,帧移一般定为帧长度的一半。
加窗
对语音信号增加一个窗函数(Window Function),在语音信号的给定区间内限定为一个实数,其它部分为0。使用的是汉明窗(Hamming Window)汉明窗的时间域表达给出:
其中$𝑛$是时间,$w(n)$是窗函数。
语谱图特征提取
语谱图(Spectrogram)是语音处理的一个重要特征,是一种描述语音信号的各个频率成分随着时间变换的热力图。
语谱图包含着语音信号的重要信息,用一个二维矩阵表示。其中一个轴表示时间,另外一个轴表示频率。不同的点或者颜色代表对应语音信号能量的大小。
语谱图的提取过程一般包括:采样、傅立叶变换、连续拼接。如下图所示:
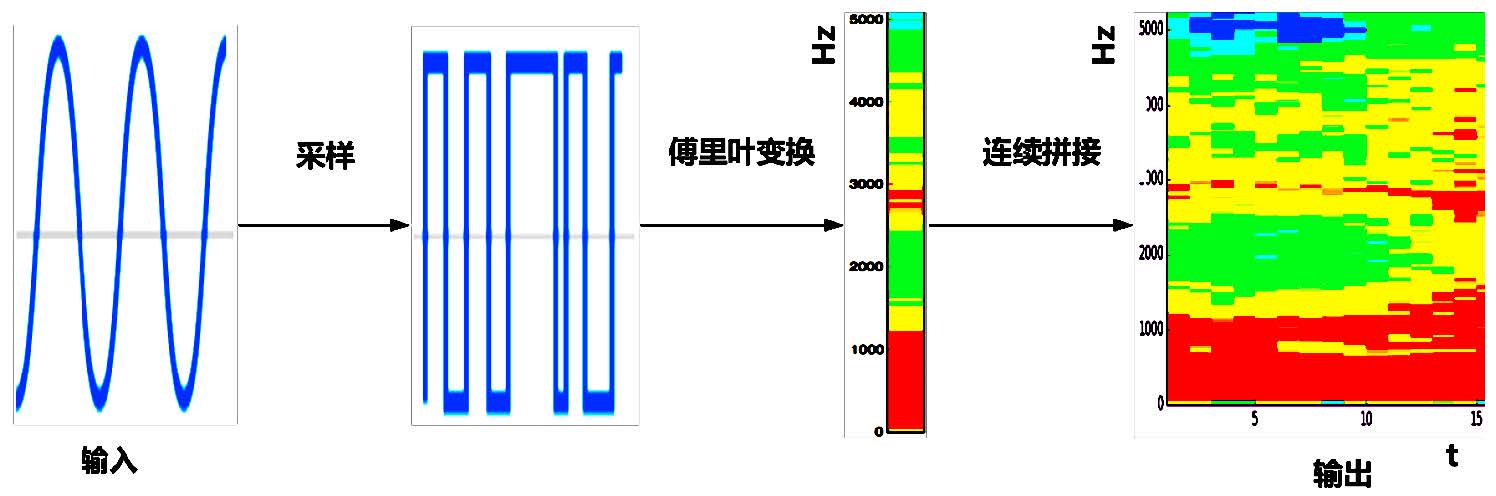
原始语音信号是符合数据格式的后缀是.wav 的原始语音数据。这里定义一个函数,读取该原始语音数据,返回声音信号的时域谱矩阵和帧速率。具体函数如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148#!/usr/bin/env python3
# -*- coding: utf-8 -*-
'''
一些通用函数,如wav文件读取、信号出来和测试代码
'''
import os
import wave
import numpy as np
import matplotlib.pyplot as plt
import math
import time
from python_speech_features import mfcc
from python_speech_features import delta
from python_speech_features import logfbank
from scipy.fftpack import fft
def read_wav_data(filename):
'''
读取一个wav文件,返回声音信号的时域谱矩阵和播放时间
'''
wav = wave.open(filename,"rb") # 打开一个wav格式的声音文件流
num_frame = wav.getnframes() # 获取帧数
num_channel=wav.getnchannels() # 获取声道数
framerate=wav.getframerate() # 获取帧速率
num_sample_width=wav.getsampwidth() # 获取实例的比特宽度,即每一帧的字节数
str_data = wav.readframes(num_frame) # 读取全部的帧
wav.close() # 关闭流
wave_data = np.fromstring(str_data, dtype = np.short) # 将声音文件数据转换为数组矩阵形式
wave_data.shape = -1, num_channel # 按照声道数将数组整形,单声道时候是一列数组,双声道时候是两列的矩阵
wave_data = wave_data.T # 将矩阵转置
return wave_data, framerate
def GetMfccFeature(wavsignal, fs):
# 获取输入特征
feat_mfcc=mfcc(wavsignal[0],fs)
feat_mfcc_d=delta(feat_mfcc,2)
feat_mfcc_dd=delta(feat_mfcc_d,2)
# 返回值分别是mfcc特征向量的矩阵及其一阶差分和二阶差分矩阵
wav_feature = np.column_stack((feat_mfcc, feat_mfcc_d, feat_mfcc_dd))
return wav_feature
x=np.linspace(0, 400 - 1, 400, dtype = np.int64)
w = 0.54 - 0.46 * np.cos(2 * np.pi * (x) / (400 - 1) ) # 汉明窗
def GetFrequencyFeature3(wavsignal, fs):
# wav波形 加时间窗以及时移10ms
time_window = 25 # 单位ms
window_length = fs / 1000 * time_window # 计算窗长度的公式,目前全部为400固定值
wav_arr = np.array(wavsignal)
#wav_length = len(wavsignal[0])
wav_length = wav_arr.shape[1]
range0_end = int(len(wavsignal[0])/fs*1000 - time_window) // 10 # 计算循环终止的位置,也就是最终生成的窗数
data_input = np.zeros((range0_end, 200), dtype = np.float) # 用于存放最终的频率特征数据
data_line = np.zeros((1, 400), dtype = np.float)
for i in range(0, range0_end):
p_start = i * 160
p_end = p_start + 400
data_line = wav_arr[0, p_start:p_end]
data_line = data_line * w # 加窗
data_line = np.abs(fft(data_line)) / wav_length
data_input[i]=data_line[0:200] # 设置为400除以2的值(即200)是取一半数据,因为是对称的
#print(data_input.shape)
data_input = np.log(data_input + 1)
return data_input
def wav_scale(energy):
'''
语音信号能量归一化
'''
means = energy.mean() # 均值
var=energy.var() # 方差
e=(energy-means)/math.sqrt(var) # 归一化能量
return e
def wav_show(wave_data, fs): # 显示出来声音波形
time = np.arange(0, len(wave_data)) * (1.0/fs) # 计算声音的播放时间,单位为秒
# 画声音波形
#plt.subplot(211)
plt.plot(time, wave_data)
#plt.subplot(212)
#plt.plot(time, wave_data[1], c = "g")
plt.show()
def get_wav_list(filename):
'''
读取一个wav文件列表,返回一个存储该列表的字典类型值
'''
txt_obj=open(filename,'r') # 打开文件并读入
txt_text=txt_obj.read()
txt_lines=txt_text.split('\n') # 文本分割
dic_filelist={} # 初始化字典
list_wavmark=[] # 初始化wav列表
for i in txt_lines:
if(i!=''):
txt_l=i.split(' ')
dic_filelist[txt_l[0]] = txt_l[1]
list_wavmark.append(txt_l[0])
txt_obj.close()
return dic_filelist,list_wavmark
def get_wav_symbol(filename):
'''
读取指定数据集中,所有wav文件对应的语音符号
返回一个存储符号集的字典类型值
'''
txt_obj=open(filename,'r') # 打开文件并读入
txt_text=txt_obj.read()
txt_lines=txt_text.split('\n') # 文本分割
dic_symbol_list={} # 初始化字典
list_symbolmark=[] # 初始化symbol列表
for i in txt_lines:
if(i!=''):
txt_l=i.split(' ')
dic_symbol_list[txt_l[0]]=txt_l[1:]
list_symbolmark.append(txt_l[0])
txt_obj.close()
return dic_symbol_list,list_symbolmark
if(__name__=='__main__'):
wave_data, fs = read_wav_data("A2_0.wav")
wav_show(wave_data[0],fs)
t0=time.time()
freimg = GetFrequencyFeature(wave_data,fs)
t1=time.time()
print('time cost:',t1-t0)
freimg = freimg.T
plt.subplot(111)
plt.imshow(freimg)
plt.colorbar(cax=None,ax=None,shrink=0.5)
plt.show()
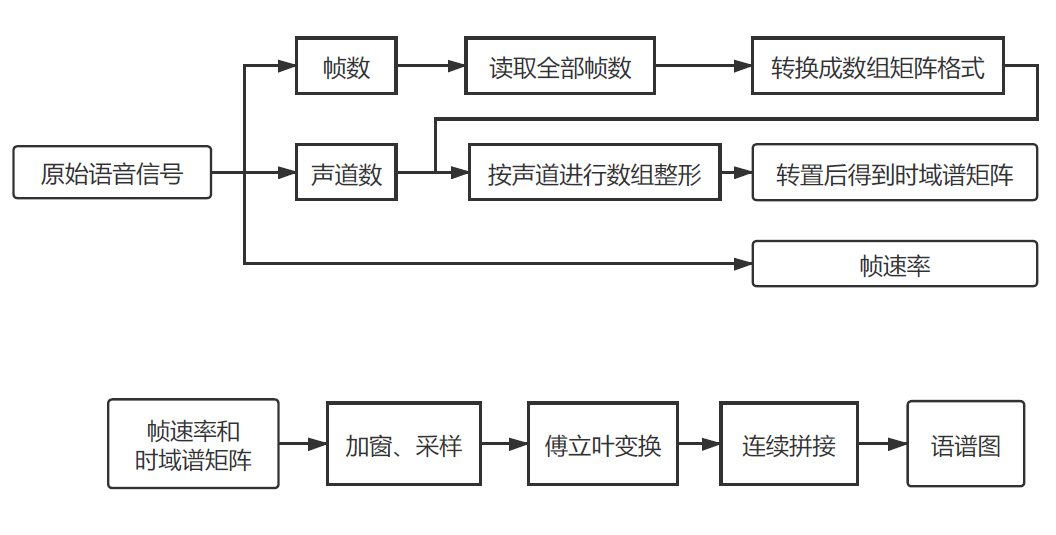
原始语音信号经过处理后得到帧数、声道数、帧速率。然后读取全部帧数,再经过变换后转换成数组矩阵格式,该数组按照声道数进行数组整形,整形后数组转置得到时域谱矩阵,得到帧速率和时域谱矩阵。在得到帧速率和时域谱矩阵后,经过加窗、采样后、傅里叶变换,以及最后的连续拼接。流程图如下:
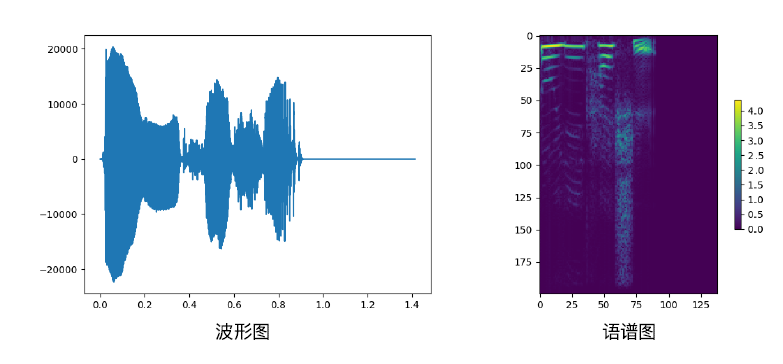
下图是采用上述代码对中文语音数据提取的波形图和语谱图的结果。波形图的横轴是时间,纵轴可以理解为位移或者压强。语谱图的横轴是拼接的时间,纵轴是频率。
声学模型设计训练
声学模型输⼊入是语谱图,输出是拼音。如下图所示:
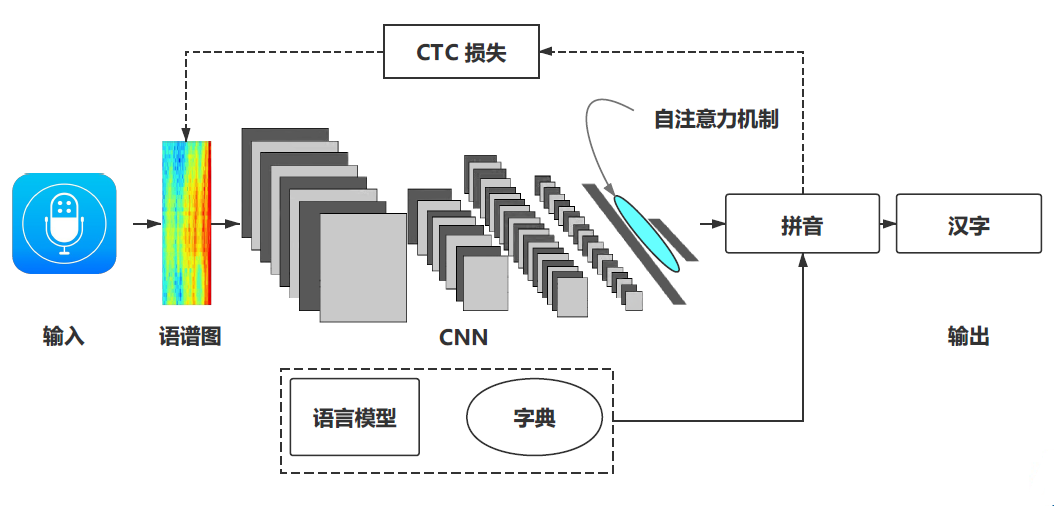
声学模型设计主要基于DFCNN网络进行训练,主要设计的结构和相应的参数设置如下:

参数设置:
Adam 的参数:
(lr = 0.01, beta_1 = 0.9,beta_2 = 0.999, decay = 0.0, epsilon = 10e-8)

CTC是一种针对序列列深度模型的损失函数。相⽐比传统交叉熵损失函数能⾃自动对⻬齐序列列标签,端到端训练模型。具体参考这里
使用Keras搭建序贯(Sequential)模型,部分代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354#!/usr/local/bin/python
# -*- coding: utf-8 -*-
"""
声学模型
"""
import platform as plat
import os
import time
from general_function.file_wav import *
from general_function.file_dict import *
from general_function.gen_func import *
from general_function.muti_gpu import *
from keras.utils import multi_gpu_model,plot_model
import tensorflow as tf
import keras as kr
import numpy as np
import random
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Input, Reshape, BatchNormalization # , Flatten
from keras.layers import Lambda, TimeDistributed, Activation,Conv2D, MaxPooling2D #, Merge
from keras import backend as K
from keras.optimizers import SGD, Adadelta, Adam, RMSprop
from ReadData import DataSpeech
abspath = ''
ModelName='_dfcnn'
#NUM_GPU = 2
base_count=0
class ModelSpeech(): # 语音模型类
def __init__(self, datapath):
'''
初始化
默认输出的拼音的表示大小是1434,即1433个拼音+1个空白块
'''
MS_OUTPUT_SIZE = 1434
self.MS_OUTPUT_SIZE = MS_OUTPUT_SIZE # 神经网络最终输出的每一个字符向量维度的大小
#self.BATCH_SIZE = BATCH_SIZE # 一次训练的batch
self.label_max_string_length = 64
self.AUDIO_LENGTH = 1600 ## 16s
self.AUDIO_FEATURE_LENGTH = 200
self._model, self.base_model = self.CreateModel()
self.datapath = datapath
self.slash = ''
system_type = plat.system() # 由于不同的系统的文件路径表示不一样,需要进行判断
if(system_type == 'Windows'):
self.slash='\\' # 反斜杠
elif(system_type == 'Linux'):
self.slash='/' # 正斜杠
else:
print('*[Message] Unknown System\n')
self.slash='/' # 正斜杠
if(self.slash != self.datapath[-1]): # 在目录路径末尾增加斜杠
self.datapath = self.datapath + self.slash
def CreateModel(self):
'''
定义DFCNN模型,使用函数式模型
输入层:200维的特征值序列,一条语音数据的最大长度设为1600(大约16s)
隐藏层:卷积池化层,卷积核大小为3x3,池化窗口大小为2
隐藏层:全连接层
输出层:全连接层,神经元数量为self.MS_OUTPUT_SIZE,使用softmax作为激活函数,
CTC层:使用CTC的loss作为损失函数,实现连接性时序多输出
'''
input_data = Input(name='the_input', shape=(self.AUDIO_LENGTH, self.AUDIO_FEATURE_LENGTH, 1))
layer_h1 = Conv2D(32, (3,3), use_bias=False, activation='relu', padding='same', kernel_initializer='he_normal')(input_data) # 卷积层
layer_h1 = BatchNormalization(mode=0,axis=-1)(layer_h1)
layer_h2 = Conv2D(32, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h1) # 卷积层
layer_h2 = BatchNormalization(axis=-1)(layer_h2)
layer_h3 = MaxPooling2D(pool_size=2, strides=None, padding="valid")(layer_h2) # 池化层 800*100
layer_h4 = Conv2D(64, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h3) # 卷积层
layer_h4 = BatchNormalization(axis=-1)(layer_h4)
layer_h5 = Conv2D(64, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h4) # 卷积层
layer_h5 = BatchNormalization(axis=-1)(layer_h5)
layer_h6 = MaxPooling2D(pool_size=2, strides=None, padding="valid")(layer_h5) # 池化层 400*50
layer_h7 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h6) # 卷积层
layer_h7 = BatchNormalization(axis=-1)(layer_h7)
layer_h8 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h7) # 卷积层
layer_h8 = BatchNormalization(axis=-1)(layer_h8)
layer_h9 = MaxPooling2D(pool_size=2, strides=None, padding="valid")(layer_h8) # 池化层 200*25
layer_h10 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h9) # 卷积层
layer_h10 = BatchNormalization(axis=-1)(layer_h10)
layer_h11 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h10) # 卷积层
layer_h11 = BatchNormalization(axis=-1)(layer_h11)
layer_h12 = MaxPooling2D(pool_size=1, strides=None, padding="valid")(layer_h11) # 池化层 200*25
layer_h13 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h12) # 卷积层
layer_h13 = BatchNormalization(axis=-1)(layer_h13)
layer_h14 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h13) # 卷积层
layer_h14 = BatchNormalization(axis=-1)(layer_h14)
layer_h15 = MaxPooling2D(pool_size=1, strides=None, padding="valid")(layer_h14) # 池化层 None*200*25*128
layer_h16 = Reshape((200, 3200))(layer_h15)
layer_h17 = Dense(128, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h16) # 全连接层
layer_h17 = BatchNormalization(axis=1)(layer_h17)
layer_h18 = Dense(self.MS_OUTPUT_SIZE, use_bias=True, kernel_initializer='he_normal')(layer_h17) # 全连接层
layer_h18 = BatchNormalization(axis=1)(layer_h18)
y_pred = Activation('softmax', name='Activation0')(layer_h18)
model_data = Model(inputs = input_data, outputs = y_pred)
model_data.summary()
labels = Input(name='the_labels', shape=[self.label_max_string_length], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
# Keras doesn't currently support loss funcs with extra parameters
# so CTC loss is implemented in a lambda layer
# CTC
loss_out = Lambda(self.ctc_lambda_func, output_shape=(1,), name='ctc')([y_pred, labels, input_length, label_length])
model = Model(inputs=[input_data, labels, input_length, label_length], outputs=loss_out)
opt = Adam(lr = 0.001, beta_1 = 0.9, beta_2 = 0.999, decay = 0.0, epsilon = 10e-8)
#model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=sgd)
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer = opt)
# captures output of softmax so we can decode the output during visualization
test_func = K.function([input_data], [y_pred])
print('[*提示] 创建模型成功,模型编译成功')
return model, model_data
def ctc_lambda_func(self, args):
y_pred, labels, input_length, label_length = args
y_pred = y_pred[:, :, :]
#y_pred = y_pred[:, 2:, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
def TrainModel(self, datapath, epoch = 2, save_step = 1000, batch_size = 32, filename = abspath + 'model_speech/m' + ModelName + '/speech_model'+ModelName):
'''
训练模型
参数:
datapath: 数据保存的路径
epoch: 迭代轮数
save_step: 每多少步保存一次模型
filename: 默认保存文件名,不含文件后缀名
'''
data=DataSpeech(datapath, 'train')
num_data = data.GetDataNum() # 获取数据的数量
yielddatas = data.data_genetator(batch_size, self.AUDIO_LENGTH)
for epoch in range(epoch): # 迭代轮数
print('[running] train epoch %d .' % epoch)
n_step = 0 # 迭代数据数
while True:
try:
print('[message] epoch %d . Have train datas %d+'%(epoch, n_step*save_step))
# data_genetator是一个生成器函数
#self._model.fit_generator(yielddatas, save_step, nb_worker=2)
self._model.fit_generator(yielddatas, save_step)
n_step += 1
except StopIteration:
print('[error] generator error. please check data format.')
break
self.SaveModel(comment='_e_'+str(epoch)+'_step_'+str(n_step * save_step))
self.TestModel(self.datapath, str_dataset='train', data_count = 4)
self.TestModel(self.datapath, str_dataset='dev', data_count = 4)
def LoadModel(self,filename = abspath + 'model_speech/m'+ModelName+'/speech_model'+ModelName+'.model'):
'''
加载模型参数
'''
self._model.load_weights(filename)
self.base_model.load_weights(filename + '.base')
def SaveModel(self,filename = abspath + 'model_speech/m'+ModelName+'/speech_model'+ModelName,comment=''):
'''
保存模型参数
'''
self._model.save_weights(filename + comment + '.model')
self.base_model.save_weights(filename + comment + '.model.base')
def TestModel(self, datapath='', str_dataset='dev', data_count = 32,comment = '', out_report = False, show_ratio = True, io_step_print = 10, io_step_file = 10):
'''
测试检验模型效果
io_step_print
为了减少测试时标准输出的io开销,可以通过调整这个参数来实现
io_step_file
为了减少测试时文件读写的io开销,可以通过调整这个参数来实现
'''
data=DataSpeech(self.datapath, str_dataset)
#data.LoadDataList(str_dataset)
num_data = data.GetDataNum() # 获取数据的数量
if(data_count <= 0 or data_count > num_data): # 当data_count为小于等于0或者大于测试数据量的值时,则使用全部数据来测试
data_count = num_data
try:
ran_num = random.randint(0,num_data - 1) # 获取一个随机数
words_num = 0
word_error_num = 0
nowtime = time.strftime('%Y%m%d_%H%M%S',time.localtime(time.time()))
if(out_report == True):
txt_obj = open(abspath+'Test_Report_' + str_dataset + '_' + nowtime + '.txt', 'w', encoding='UTF-8') # 打开文件并读入
txt = '测试报告\n模型编号 ' + ModelName + '\n\n'
for i in range(data_count):
data_input, data_labels = data.GetData((ran_num + i) % num_data) # 从随机数开始连续向后取一定数量数据
# 数据格式出错处理 开始
# 当输入的wav文件长度过长时自动跳过该文件,转而使用下一个wav文件来运行
num_bias = 0
while(data_input.shape[0] > self.AUDIO_LENGTH):
print('*[Error]','wave data lenghth of num',(ran_num + i) % num_data, 'is too long.','\n A Exception raise when test Speech Model.')
num_bias += 1
data_input, data_labels = data.GetData((ran_num + i + num_bias) % num_data) # 从随机数开始连续向后取一定数量数据
# 数据格式出错处理 结束
pre = self.Predict(data_input, data_input.shape[0] // 8)
words_n = data_labels.shape[0] # 获取每个句子的字数
words_num += words_n # 把句子的总字数加上
edit_distance = GetEditDistance(data_labels, pre) # 获取编辑距离
if(edit_distance <= words_n): # 当编辑距离小于等于句子字数时
word_error_num += edit_distance # 使用编辑距离作为错误字数
else: # 否则肯定是增加了一堆乱七八糟的奇奇怪怪的字
word_error_num += words_n # 就直接加句子本来的总字数就好了
if((i % io_step_print == 0 or i == data_count - 1) and show_ratio == True):
#print('测试进度:',i,'/',data_count)
print('Test Count: ',i,'/',data_count)
txt = ''
if(out_report == True):
# if(i % io_step_file == 0 or i == data_count - 1):
# txt_obj.write(txt)
# txt = ''
txt += str(i) + '\n'
txt += 'True:\t' + str(data_labels) + '\n'
txt += 'Pred:\t' + str(pre) + '\n'
txt += '\n'
txt_obj.write(txt)
print('*[Test Result] Speech Recognition ' + str_dataset + ' set word error ratio: ', word_error_num / words_num * 100, '%')
if(out_report == True):
txt += '*[测试结果] 语音识别 ' + str_dataset + ' 集语音单字错误率: ' + str(word_error_num / words_num * 100) + ' %'
txt_obj.write(txt)
txt = ''
txt_obj.close()
except StopIteration:
print('[Error] Model Test Error. please check data format.')
def Predict(self, data_input, input_len):
'''
预测结果
返回语音识别后的拼音符号列表
'''
batch_size = 1
in_len = np.zeros((batch_size),dtype = np.int32)
in_len[0] = input_len
x_in = np.zeros((batch_size, 1600, self.AUDIO_FEATURE_LENGTH, 1), dtype=np.float)
for i in range(batch_size):
x_in[i,0:len(data_input)] = data_input
base_pred = self.base_model.predict(x = x_in)
base_pred =base_pred[:, :, :]
r = K.ctc_decode(base_pred, in_len, greedy = True, beam_width=100, top_paths=1)
#print('r', r)
r1 = K.get_value(r[0][0])
#print('r1', r1)
#r2 = K.get_value(r[1])
#print(r2)
r1=r1[0]
return r1
pass
def RecognizeSpeech(self, wavsignal, fs):
'''
最终做语音识别用的函数,识别一个wav序列的语音
'''
#data = self.data
#data = DataSpeech('E:\\语音数据集')
#data.LoadDataList('dev')
# 获取输入特征
#data_input = GetMfccFeature(wavsignal, fs)
#t0=time.time()
data_input = GetFrequencyFeature(wavsignal, fs)
#t1=time.time()
#print('time cost:',t1-t0)
input_length = len(data_input)
input_length = input_length // 8
data_input = np.array(data_input, dtype = np.float)
#print(data_input,data_input.shape)
data_input = data_input.reshape(data_input.shape[0],data_input.shape[1],1)
#t2=time.time()
r1 = self.Predict(data_input, input_length)
#t3=time.time()
#print('time cost:',t3-t2)
list_symbol_dic = GetSymbolList(self.datapath) # 获取拼音列表
r_str=[]
for i in r1:
r_str.append(list_symbol_dic[i])
return r_str
pass
def RecognizeSpeech_FromFile(self, filename):
'''
最终做语音识别用的函数,识别指定文件名的语音
'''
wavsignal,fs = read_wav_data(filename)
r = self.RecognizeSpeech(wavsignal, fs)
return r
pass
def model(self):
'''
返回keras model
'''
return self._model
