在浏览器的地址栏输入一个URL,然后回车,回车这一瞬间到看到页面到底发生了什么呢?
主要是进行了一下几个步骤:
1.DNS域名解析;
2.建立TCP连接;
3.发送http请求;
4.服务器处理请求;
5.返回响应结果;
6.关闭TCP连接;
7.浏览器解析HTML;
8.浏览器布局渲染;
DNS域名解析
我们在浏览器输入网址,其实就是要向服务器请求我们想要的页面内容,所有浏览器首先要确认的是域名所对应的服务器在哪里。将域名解析成对应的服务器IP地址这项工作,是由DNS服务器来完成的。
客户端收到你输入的域名地址后,一般会经历以下几个步骤:
Chrome浏览器会首先搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存),看自身的缓存中是否有www.baidu.com对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
注:我们怎么查看Chrome自身的缓存?可以使用 chrome://net-internals/#dns 来进行查看如果浏览器自身的缓存里面没有找到对应的条目,那么Chrome会搜索操作系统自身的DNS缓存,如果找到且没有过期则停止搜索解析到此结束.
注:怎么查看操作系统自身的DNS缓存,以Windows系统为 例,可以在命令行下使用 ipconfig /displaydns 来进行查看如果在Windows系统的DNS缓存也没有找到,那么尝试读取hosts文件(位于C:\Windows\System32\drivers\etc),看看这里面有没有该域名对应的IP地址,如果有则解析成功。
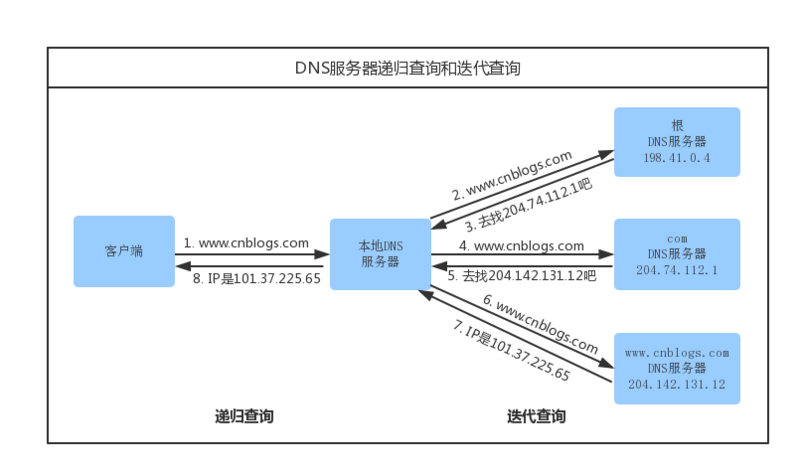
如果在hosts文件中也没有找到对应的条目,浏览器就会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器(一般是电信运营商提供的,也可以使用像Google提供的DNS服务器)发起域名解析请求(通过的是UDP协议向DNS的53端口发起请求,这个请求是递归的请求,也就是运营商的DNS服务器必须得提供给我们该域名的IP地址),运营商的DNS服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。如果没有找到对应的条目,则有运营商的DNS代我们的浏览器发起迭代DNS解析请求,它首先是会找根域的DNS的IP地址(这个DNS服务器都内置13台根域的DNS的IP地址),找打根域的DNS地址,就会向其发起请求(请问www.baidu.com这个域名的IP地址是多少啊?),根域发现这是一个顶级域com域的一个域名,于是就告诉运营商的DNS我不知道这个域名的IP地址,但是我知道com域的IP地址,你去找它去,于是运营商的DNS就得到了com域的IP地址,又向com域的IP地址发起了请求(请问www.baidu.com这个域名的IP地址是多少?),com域这台服务器告诉运营商的DNS我不知道www.baidu.com这个域名的IP地址,但是我知道baidu.com这个域的DNS地址,你去找它去,于是运营商的DNS又向baidu.com这个域名的DNS地址(这个一般就是由域名注册商提供的,像万网,新网等)发起请求(请问www.baidu.com这个域名的IP地址是多少?),这个时候baidu.com域的DNS服务器一查,诶,果真在我这里,于是就把找到的结果发送给运营商的DNS服务器,这个时候运营商的DNS服务器就拿到了www.baidu.com这个域名对应的IP地址,并返回给Windows系统内核,内核又把结果返回给浏览器,终于浏览器拿到了www.baidu.com 对应的IP地址,该进行一步的动作了。
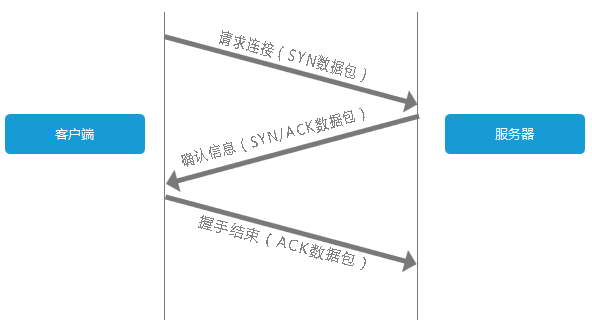
建立TCP连接
费了一顿周折终于拿到服务器IP了,下一步自然就是链接到该服务器。对于客户端与服务器的TCP链接,必然要说的就是『三次握手』。
为什么HTTP协议要基于TCP来实现?
目前在Internet中所有的传输都是通过TCP/IP进行的,HTTP协议作为TCP/IP模型中应用层的协议也不例外,TCP是一个端到端的可靠的面向连接的协议,所以HTTP基于传输层TCP协议不用担心数据的传输的各种问题。
发送HTTP请求
与服务器建立了连接后,就可以向服务器发起请求了。这里我们先看下请求报文的结构(如下图):
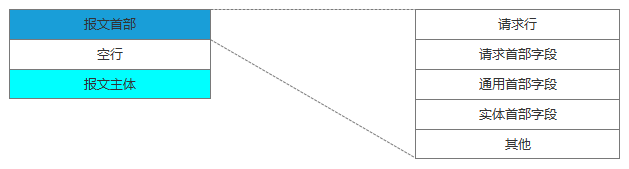
请求报文
在浏览器中查看报文首部(以google浏览器为例):
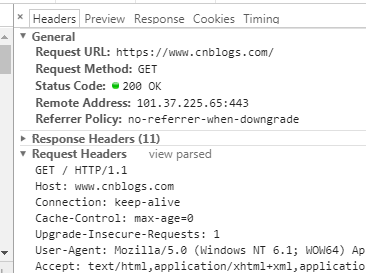
请求行包括请求方法、URI、HTTP版本。首部字段传递重要信息,包括请求首部字段、通用首部字段和实体首部字段。我们可以从报文中看到发出的请求的具体信息。具体每个首部字段的作用,这里不做过多阐述。
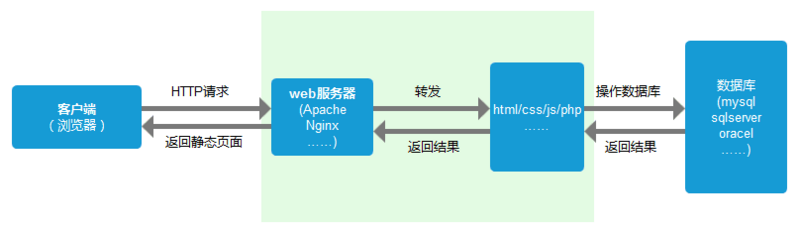
服务器处理请求
服务器端收到请求后的由web服务器(准确说应该是http服务器)处理请求,诸如Apache、Ngnix、IIS等。web服务器解析用户请求,知道了需要调度哪些资源文件,再通过相应的这些资源文件处理用户请求和参数,并调用数据库信息,最后将结果通过web服务器返回给浏览器客户端。
返回响应结果
在HTTP里,有请求就会有响应,哪怕是错误信息。这里我们同样看下响应报文的组成结构:
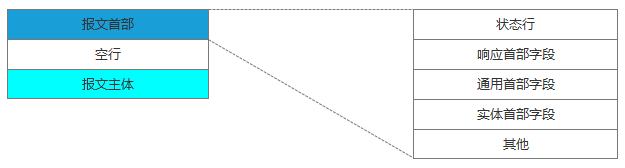
响应报文
在响应结果中都会有个一个HTTP状态码,比如我们熟知的200、301、404、500等。通过这个状态码我们可以知道服务器端的处理是否正常,并能了解具体的错误。
状态码由3位数字和原因短语组成。根据首位数字,状态码可以分为五类:
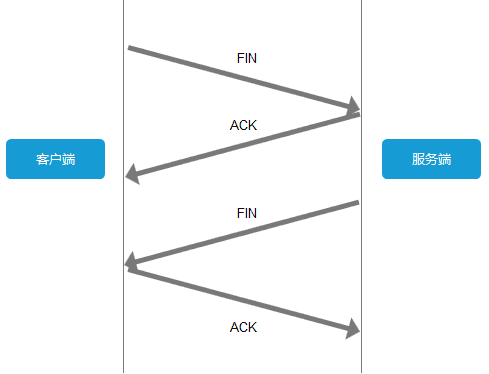
关闭TCP连接
为了避免服务器与客户端双方的资源占用和损耗,当双方没有请求或响应传递时,任意一方都可以发起关闭请求。与创建TCP连接的3次握手类似,关闭TCP连接,需要4次握手。
浏览器解析HTML
准确地说,浏览器需要加载解析的不仅仅是HTML,还包括CSS、JS。以及还要加载图片、视频等其他媒体资源。
浏览器通过解析HTML,生成DOM树,解析CSS,生成CSS规则树,然后通过DOM树和CSS规则树生成渲染树。渲染树与DOM树不同,渲染树中并没有head、display为none等不必显示的节点。
要注意的是,浏览器的解析过程并非是串连进行的,比如在解析CSS的同时,可以继续加载解析HTML,但在解析执行JS脚本时,会停止解析后续HTML,这就会出现阻塞问题
浏览器布局渲染
根据渲染树布局,计算CSS样式,即每个节点在页面中的大小和位置等几何信息。HTML默认是流式布局的,CSS和js会打破这种布局,改变DOM的外观样式以及大小和位置。这时就要提到两个重要概念:replaint和reflow。
replaint:屏幕的一部分重画,不影响整体布局,比如某个CSS的背景色变了,但元素的几何尺寸和位置不变。
reflow: 意味着元件的几何尺寸变了,我们需要重新验证并计算渲染树。是渲染树的一部分或全部发生了变化。这就是Reflow,或是Layout。
所以我们应该尽量减少reflow和replaint,我想这也是为什么现在很少有用table布局的原因之一。
最后浏览器绘制各个节点,将页面展示给用户。
